

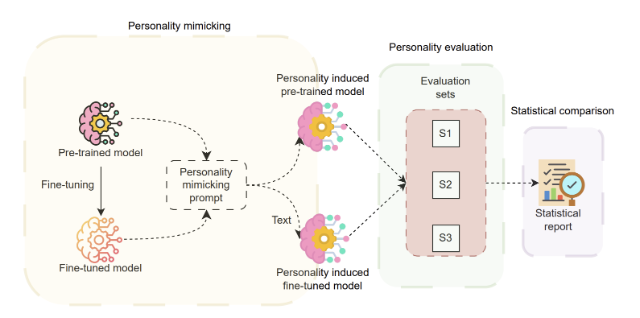
Can Large Language Models Mimic Human Personality?
Can a language model be given a stable personality that shows up consistently in its answers? That is the central question behind Can Large Language Models Mimic Human Personality? by Prateek Kumar Rajput, Tegawende F. Bissyande, and Jacques Klein. The team tests this idea using a classic psychology essays dataset paired with Big Five labels, plus a standard personality questionnaire, to see what works, what does not, and what remains uncertain.
Scope note
All results reported below come from Phase 1 of the project. Phase 2 is ongoing and will study stronger and larger models, including scaling from 7B to 70B parameters and introducing a separate reward model.
The Challenge of This Research
Turning personality into something an AI can express raises three hurdles:
- Prompt sensitivity
Models can change their answers when the wording changes, which weakens evaluation.
- Signal in free text
Teaching a model who it is from long essays is difficult because personality cues are not always clear.
- Confounding factors
Alignment settings and model size might influence results, so the study must separate these effects.
The Methods
- Data and models
The study uses the Essays Dataset with 2,467 essays and Big Five labels, and evaluates multiple models from small open models up to GPT-3.5.
- Evaluation for stability
Multiple versions of the same questionnaire are used to check whether answers stay consistent when prompts are rephrased.
- Training recipes
The team tries supervised fine-tuning on the essays, and preference-based fine-tuning methods including DPO and ORPO. In a separate experiment, they include parts of the questionnaire in the training data to test whether the model can better link essays to trait scores.
- General compute setup
Training runs use NVIDIA A100 GPUs with parameter-efficient techniques such as LoRA and QLoRA.
MeluXina’s Contribution
The supercomputer enabled many repeat runs for hyperparameter exploration such as learning rate and prompt choices, and avoided RAM overflow issues seen elsewhere.
Phase 1
- DPO experiments were ran for Gemma-7B and Llama-3.1-8B.
- Hardware: 2 A100 GPUs on 1 node, about 100–200 GB system memory per run, and a typical duration of about 3 hours.
- Software and parallelisation: TRL, PyTorch, PEFT or QLoRA, flash-attention, FSDP via Accelerate.
Phase 2 (ongoing)
- A separate reward model and a larger main model for personality induction is being explored
- Hardware so far: 4 A100 GPUs on 1 node, 200–300 GB memory, typical supervised fine-tuning runs of about 7–8 hours. The plan is to use an additional node so the SFT-trained model can provide rewards while the main model trains.
Findings
(Phase 1)
- Stability improves after fine-tuning
Once fine-tuned, questionnaire answers vary less when prompts are rephrased. Reported variability drops by roughly 15–33% across models and prompt styles.
- Full personality profiles remain hard
Recovering a complete five-trait vector from generated essays stays near chance. The best exact-match score over 32 combinations is 9.38%, modestly above the 3.125% random baseline. Individual traits can look reasonable on their own, yet they do not form a consistent human-like profile. Using uncensored versus security-aligned variants does not change this conclusion.
The Impact
If personality is to be a controllable setting in real products, it needs to be both stable and accurate. Phase 1 shows that targeted fine-tuning can improve stability, while genuine accuracy on full personality profiles remains out of reach when training on unguided essays. The next step, now underway in Phase 2, is to test larger models and a separate reward model to see how these choices affect both stability and accuracy.
Conclusion
Personality induction today is mixed. Fine-tuning helps models keep a steadier voice, but it does not reliably produce full human-like personality vectors from essays alone. With MeluXina’s A100 setup, Phase 1 could run repeated DPO experiments and hyperparameter sweeps without memory issues. As Phase 2 scales to larger models and introduces a dedicated reward model, MeluXina will continue to support broader experiments and faster iteration, helping the team produce clearer evidence about what truly works.