

Teaching Artificial Intelligence to Perform Rapid, Resolution-Invariant Grain Growth Modelling via Fourier Neural Operator
Introduction
Beneath the polished surface of metal or ceramic lies a hidden mosaic of microscopic grains, each quietly shaping the material’s strength, conductivity and durability.
Traditionally, watching these grains change meant running tedious, step-by-step simulations that could take days to reveal what happens in a few seconds of real time. To change that, Dr. Salim Belouettar, Iman Peivaste, & Ahmed Makradi from LIST (Luxembourg Institute of Science and Technology) built a Fourier Neural Operator (FNO) surrogate that learns grain-growth rules once and applies them at any scale.
With MeluXina’s computing power behind them, the team generated training data via the Allen–Cahn Fan–Chen model and demonstrated the ability of a single model to predict grain-growth dynamics from coarse to fine grids with minimal error and dramatic speedups.
The Challenges of This Research
Understanding and forecasting grain growth across different scales brings three main obstacles:
- Heavy Simulation Cost: Phase-field simulations over 8 000 timesteps for grids up to 512×512 cells demand extensive compute time and memory.
- Resolution dependence: Conventional machine-learning models need fresh training whenever the resolution changes, making it impractical to apply the same surrogate from low-res to high-res without starting over.
- Boundary conditions: Grain structures wrap around from one edge of the simulation box to the other. Any surrogate must handle these periodic boundaries gracefully to avoid visual or physical artefacts.
The MeluXina-Powered Approach
To tackle these challenges, the team devised a workflow on MeluXina, incorporating data generation, FNO training and rigorous benchmarking as follows:
- Dataset generation and preprocessing
- Ran phase-field simulations with the Fan–Chen Allen–Cahn model on grids of 64×64, 128×128, 256×256 and 512×512, saving snapshots every 100 timesteps.
- Created input–output pairs with five-frame sequences and a skip step of five, augmenting data via overlapping strides and filtering trivial steady-state cases.
- Resolution-invariant FNO training
- Lifted input microstructures into a 20-channel feature space, applied four spectral convolution layers with 20 retained Fourier modes, and projected back to the order-parameter field.
- Trained and tuned about 10 million parameters over 400 epochs on MeluXina’s GPUs.
- Benchmarking and validation
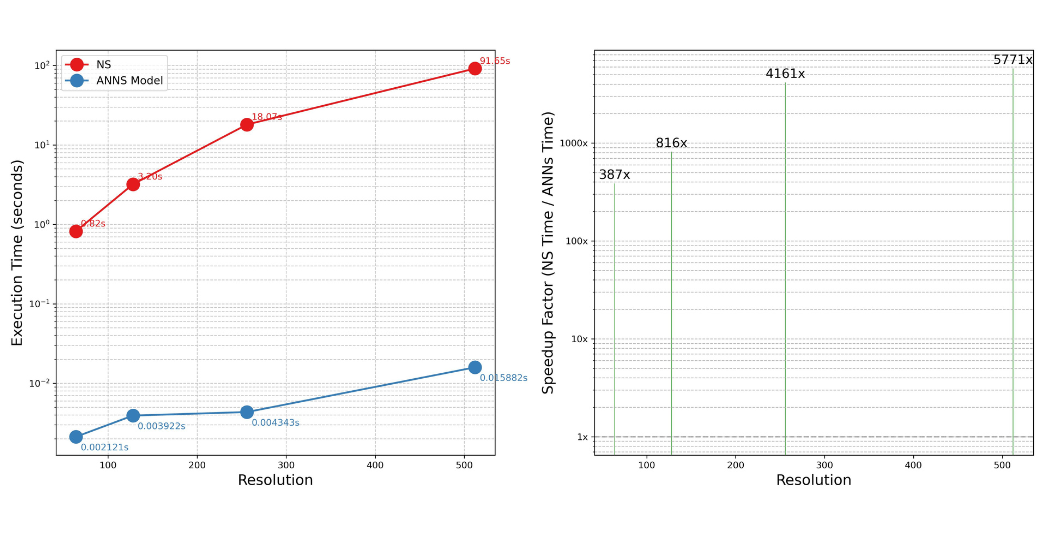
- Tested on unseen microstructures and resolutions, measuring MAE below 7×10⁻⁴ across 64–512 grids and speedups up to 5 770× compared to the numerical solver.
The Impact
Putting this FNO surrogate through MeluXina revealed three standout benefits:
- Accurate long-term predictions; FNO recreates grain-boundary migration over 1 000 timesteps with pointwise errors under 0.0006, capturing topology changes and coarsening trends.
- True resolution invariance: A single trained model generalises from coarse to fine grids without retraining, maintaining MAE between 0.0006 and 0.0007.
- Dramatic speedups: Inference times remain near‐constant as resolution grows, delivering thousands‐fold faster predictions for high-resolution simulations.
Conclusion
By weaving together, a resolution-invariant Fourier Neural Operator with MeluXina’s raw compute power, this study not only uncovers rich insights into how grains coarsen but also delivers a tool that makes real-time microstructure prediction a reality. With errors under 7×10⁻⁴ across all scales and speedups up to 5 770×, researchers can now explore new materials and designs at unprecedented pace.